DynamoDB in examples, Example 1: User wallet table
Finally I decide that I spent enough time and made enough mistakes using dynamodb to write my small tutorial for it. I am going to show few examples of dynamodb usage because of I didn't find good enough 'close to real life' examples. If You haven't any experience with dynamodb, I recommend to start from dynamodb documentation, or these books:
and use these posts as source of examples.
To run examples code locally, You need to install botocore and place your amazon access keys to ~/.boto file:
[Credentials] aws_access_key_id=AK... aws_secret_access_key=6t...
In the first example I use amazon dynamodb api service, but later I'll show how to use local dynamodb instead. It may be useful for local development, tests.
Setup virtual environment and install botocore:
virtualenv .env --no-site-packages -p /usr/local/bin/python3.3
source .env/bin/activate
pip install botocore
Don't forget to remove tables after finish experiments with them, Amazon may charge You unexpectedly after few months service usage (even if You did not use them, we pay for throughput and storage, not usage).
This is the simplest example of dynamodb usage I was able to invent: key/value user wallet table. We will have only one table with two columns: user_id and balance.
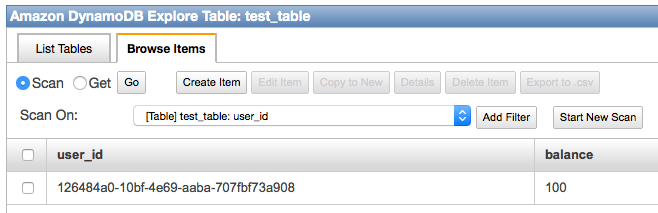
import botocore.session import logging import uuid logger = logging.getLogger() TABLE_NAME = 'test_table' if __name__ == '__main__': session = botocore.session.get_session() ddb = session.get_service(service_name='dynamodb') endpoint = ddb.get_endpoint('us-west-2') # check is table exists response, message = ddb.get_operation(operation_name='DescribeTable').call( endpoint=endpoint, TableName=TABLE_NAME) if 'Error' in message and message['Error']['Code'] == 'ResourceNotFoundException': logger.warning('Table does not exists.') # create table response, message = ddb.get_operation(operation_name='CreateTable').call( endpoint=endpoint, TableName=TABLE_NAME, AttributeDefinitions=[{ 'AttributeName': 'user_id', 'AttributeType': 'S'}], KeySchema=[{ 'AttributeName': 'user_id', 'KeyType': 'HASH', }], ProvisionedThroughput={ 'ReadCapacityUnits': 1, 'WriteCapacityUnits': 1 }) logger.warning(message) """ { 'ResponseMetadata':{ 'HTTPStatusCode':200, 'RequestId':'MK6Q0RMF6T3C88VR6A1GI8F95NVV4KQNSO5AEMVJF66Q9ASUAAJG' }, 'TableDescription':{ 'KeySchema':[ { 'AttributeName':'user_id', 'KeyType':'HASH' } ], 'ProvisionedThroughput':{ 'WriteCapacityUnits':1, 'NumberOfDecreasesToday':0, 'ReadCapacityUnits':1 }, 'AttributeDefinitions':[ { 'AttributeType':'S', 'AttributeName':'user_id' } ], 'ItemCount':0, 'TableStatus':'CREATING', 'CreationDateTime':datetime.datetime(2015, 2, 21, 23, 4, 27, 81000, tzinfo=tzlocal()), 'TableSizeBytes':0, 'TableName':'test_table' } } """ else: # write a row user_id = uuid.uuid4() response, message = ddb.get_operation(operation_name='PutItem').call( endpoint=endpoint, TableName=TABLE_NAME, Item={ 'user_id': { 'S': str(user_id), }, 'balance': { 'N': str(100), } }) logger.warning(message) """ {'ResponseMetadata': {'RequestId': 'PPPUQPC05R6EUQFQ3V5HSNV6O3VV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200}} """ # and read response, message = ddb.get_operation(operation_name='GetItem').call( endpoint=endpoint, TableName=TABLE_NAME, Key={ 'user_id': { 'S': str(user_id), } }) logger.warning(message) """ { 'Item':{ 'balance':{ 'N':'100' }, 'user_id':{ 'S':'126484a0-10bf-4e69-aaba-707fbf73a908' } }, 'ResponseMetadata':{ 'RequestId':'AUMGNQSHFK7RM8D39S1D6EDSRFVV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode':200 } } """
If You wonder how I know what arguments to pass to call method, check out API reference.
Brief description of arguments I passed to CreateTable request:
- KeySchema: specify list of fields which will be used as keys
- AttributeDefinitions: specify types of required fields (ones used as key)
- ProvisionedThroughput: see below
Provisioned throughput [Documentation]
You should specify how many read/write requests You expect. Don't bother about value You need on table creation, set it to 1, You always can edit throughput using dynamodb console or using API, it requires only few minutes to update.
You pay for throughput, so better keep it as small as possible:
- use caching
- increase throughput when You expected high activity
- if You haven't permanent high load or your database is small and not growing - think about another storage
- use indexes wisely
I'll talk about all these more detailed later.
For now, remember:
- read throughput 1 == one read request with response up to 4KB per second
- write throughput 1 == one write request with items size up to 1KB per second