Scrapy
An open source and collaborative framework for extracting the data you need from websites.
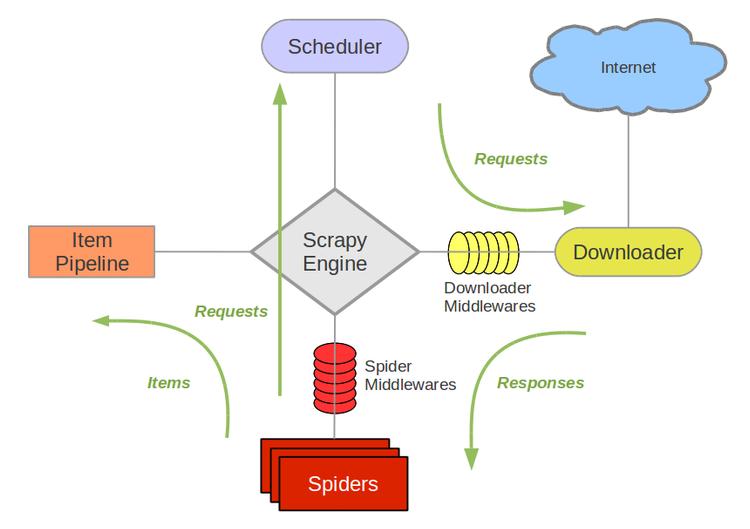
Spiders
Methods:
open_spiderclose_spider
Parse
response.urljoin - same urlparse.urljoin but with response.url as the first argument:
def parse(self.response): next_page = response.urljoin('/page/2/') yield scrapy.Request(next_page, callback=self.parse)
Form request
aka POST request.
def parse(self, response): return scrapy.FormRequest( url, formdata={'username': 'john', 'password': 'secret'}, callback=self.after_login )
Also see from_response method - returns a new FormRequest object with its form field values pre-populated with those found in the HTML form element contained in the given response.
Selectors
Selectors are a higher level interface on top of lxml. It handles broken HTML and confusing encoding.
>>> response.css('title::text').re(r'Quotes.*') ['Quotes to Scrape'] >>> response.css('title::text').re(r'Q\w+') ['Quotes'] >>> response.css('title::text').re(r'(\w+) to (\w+)') ['Quotes', 'Scrape']
XPath
Concise XPath.
XPath tutorial.
Scrapy best practices on The scrapinghub blog.
>>> from scrapy.selector import Selector >>> from scrapy.http import HtmlResponse >>> body = '<html><body><span>good</span></body></html>' >>> Selector(text=body).xpath('//span/text()').extract() [u'good'] >>> response = HtmlResponse(url='http://example.com', body=body) >>> response.selector.xpath('//span/text()').extract() [u'good'] >>> response.selector.xpath('//span/text()').extract_first() u'good'
Conditions separated by / are known as steps.
Condition inside [] is known as predicate.
// allows to get all elements of a particular type, not only those belong to the current node.
@ allows to select attributes.
More examples:
.//text() # extract all text ./table/tr[td] # select only `tr`'s contain `td` ./li[a]/parent::ul' # select `ul` that contains at least one `li` with `a` inside ./ul/li[@id="someid"]/following-sibling::li[1] # following sibling ./ul/li[@id="someid"]/preceding-sibling::li[1] # preceding siblings ./div[not(contains(@class,"somecls"))] # not contains class name(.) # get current tag name (./p | ./a) # select `p` and `a` tags ./*[self::p or self::a] # select `p` and `a` tags ./td/parent::tr/parent::table # select parent element ./../../a # a few levels upper (similar to `parent:*`)
XPath functions:
not()contains()starts-with()name()string()- converts an object to a string (different from.//text())- and more
Extraction
Use .extract() or .extract_first().
Using re: .re('\d+ (.+)') or .re_first('\d+ (.+)')
Parsing, sanitizing, and more: w3lib - a Python library of web-related functions.
Asynchronous IO
We can't write asynchronous code in spiders. As parse methods can return on dicts, Request objects and None, not deferred. What if we need some extra io:
- do it outside the spider (item pipeline)
- if there are only a few requests, or connection is fast enough (e.g. redis on localhost) - use blocking client
- do requests same way we request sites when scraping
S3 example:
from types import MethodType from botocore.endpoint import Endpoint import botocore.session from scrapy import Request import treq class BotocoreRequest(Exception): def __init__(self, request, *args, **kwargs): super(BotocoreRequest, self).__init__(*args, **kwargs) self.method = request.method # https://github.com/twisted/treq/issues/185 self.url = request.url.replace('https://', 'http://') self.headers = dict(request.headers) self.body = request.body and request.body.read() def _send_request(self, request_dict, operation_model): request = self.create_request(request_dict, operation_model) raise BotocoreRequest(request=request) class ScrapyAWSClient: def __init__(self, service, access_key, secret_key, region, timeout=30): session = botocore.session.get_session() session.set_credentials( access_key=access_key, secret_key=secret_key ) self.client = session.create_client(service, region_name=region) endpoint = self.client._endpoint endpoint._send_request = MethodType(_send_request, endpoint) self.timeout = timeout def request(self, method, callback, meta, **kwargs): try: getattr(self.client, method)(**kwargs) except BotocoreRequest as e: return Request( method=e.method, url=e.url, body=e.body, headers=e.headers, meta=meta, callback=callback, dont_filter=True ) class MySpider(Spider): def __init__(self, *args, **kwargs): super(MySpider, self).__init__(*args, **kwargs) self.client = ScrapyAWSClient( service='s3', access_key='', secret_key='', region='your-region' ) def parse(self, response): ... yield self.client.request( method='get_object', Bucket='my-s3-bucket', Key='my-key', callback=self.my_parser, meta={ 'handle_httpstatus_list': [200, 403] } )
Items
Items provide the container of scraped data, while Item Loaders provide the mechanism for populating that container.
Items and ItemLoaders are sucks
IMHO.
- Fields don't have any validation (even
is_required) - Set/get values using getvalue:
item['myvalue'] = 0
item.myvalue = 0is shorter. And I can't use my editor autocomplete (works with attributes) - ItemLoader's
in/outmethods are duplicate ofField.input/output_processors, and one needs to keep them in sync with Item fields - I can pass a dict as a first argument to ItemLoader, and it will accept it same as an Item
- Passing an item from one parser to another through request.meta looks like:
item = loader.load_item() yield Request(meta={'item': item}) item = response.meta['item'] loader = ItemLoader(item) loader.add_value('myfield', 1) yield loader.load_item()
load_item (and input/output processors) was called twice.
6. I can't copy response.xpath() or response.xpath().re_first() from scrapy console (where I do debug) 1:1 into my code (must rewrite into add_xpath(fieldname, xpath, re)). Copying xpath and re doesn't make me sure that it will work the same way as there are input/output processors
7. add_value(None, {}) looks weird
Solution: use builders instead. And schema validation.
class Builder(object): field1 = None _field2 = [] def __init__(self, field1=None): self.field1 = field1 # reset mutable attributes self._field2 = [] def __setattr__(self, name, value): """ Raise an exception if a field name was mistyped. """ if not hasattr(self, name): raise AttributeError("{name} attribute does not exist.".format(name=name)) super(OpenstatesBase, self).__setattr__(name, value) def add_field2(self, value): """ Any validation, formatting if required. """ self._field2.append(value) def copy(self): """ Code to return the object copy. If you need it. """ def load(self): """ Can use ItemLoader or/and validation here. """ return { 'field1': self.field1, 'field2': self._field2 }
Item pipelines
Use if the problem is domain specific and the pipeline can be reused across projects.
Files pipeline
Don't like s3 storage implementation: blocking botocore + threads. But it may be a good way to do it, efficient enough, reliable and stable.
Spider middlewares
Use if the problem is domain specific and the middleware can be reused across projects. Use to modify or drop items.
Useful middlewares:
scrapy_fake_useragent.middleware.RandomUserAgentMiddleware
Downloader middlewares
Use for custom login or special cookies handling.
Extensions
Plain classes that get loaded at crawl startup and can access settings, the crawler, register callbacks to signals, and define their own signals.
Close spider
CLOSESPIDER_TIMEOUT
CLOSESPIDER_ITEMCOUNT
CLOSESPIDER_PAGECOUNT
CLOSESPIDER_ERRORCOUNT
Memory usage extension
Shuts down the spider when it exceeds a memory limit.
Commands
scrapy startproject myproject [project_dir] scrapy genspider mydomain mydomain.com
Global commands:
- startproject
- genspider
- settings
- runspider
- shell
- fetch
- view
- version
Project commands:
- crawl
- check
- list
- edit
- parse
- bench
Running a spider:
scrapy crawl <spidername> -s CLOSESPIDER_ITEMCOUNT=10
Using proxy:
export http_proxy=<ip/host>:<port> scrapy crawl <spidername>
Settings
See https://doc.scrapy.org/en/1.2/topics/settings.html#built-in-settings-reference.
Command line:
scrapy shell -s SOME_SETTING=VALUE
Twisted
Twisted - hello asynchronous programming
Twisted Introduction
Introduction to Deferreds
@defer.inlineCallback accepts a function as an argument, that function can yield a deffered or call returnValue, essentially anywhere where you would normally block, you simply yield.
Deferred:
deferred = defer.Deferred()
deferred.addCallback(handler1)
deferred.addCallback(handler2)
deferred.callback('result')
reactor.callLater(60, reactor.stop)
reactor.run()
The reactor is the event loop mechanism for Twisted. It takes care of executing all of the various timed actions and the execution of the callback/errback stack. Timed actions can be deferreds, etc. Deferreds are simply objects executed by the Reactor.
treq
treq - an asynchronous equivalent for requests package.
Simpler than scrapy's Request/crowler.engine.download().
from treq import post from twisted.internet import defer class MyExtension(object): ... @defer.inlineCallbacks def spider_closed(self, spider, *args, **kwargs): response = yield post( url='http://example.com', data={ 'param': 'value' } ) json_response = yield response.json() assert json_response['ok']
Async DB clients
from twisted.internet import defer from txmongo.connection import ConnectionPool class MongoDBPipeline(object): ... @defer.inlineCallbacks def open_spider(self, spider): self.connection = yield ConnectionPool(uri='mongo://...') @defer.inlineCallbacks def close_spider(self, spider): yield self.connection.disconnect() @defer.inlineCallbacks def process_item(self, item, spider): collection = self.connection['mydb']['mycollection'] yield collection.save(dict(item)) defer.returnValue(item)
Async MQ clients
Pika (AMQP)
Use twisted_connection adapter.
A few problems with pika twisted adapter
First: if you call basic_publish too often, some messages can be not delivered to the broker. There is no errors or warnings both on basic_publish and connection.close(). Waiting for delivery confirmation solved the problem.
Another one: there is no reconnection after connection was lost. And it loses connection after a few minutes of inactivity: pika issue #820.
Using threads
reactor.CallInThread()
Use locks: threading.RLock() (issues around global state).
Run executables with reactor.spawnProcess().
Performance
Use telnet console:
telnet localhost 6023 est() # get execution engine status
See Learning Scrapy by Dimitrius Kouzis-Loukas, "Performance" chapter.
Pipeline: scheduller -> throttler -> downloader -> spider -> item pipelines.
Downloader
Default downloader timeout is 3 minutes. So if some site has a lot of broken links, it may take hours instead of minutes for a spider to finish.
Item pipeline
Blocking code slows done items processing, and it may become a bottleneck. Example: blocking db connection + slow connection.
See How does scrapy react to a blocked Ppipeline?
How fast a single spider
It depends.
I saw 20rps, but with aiohttp able to reach 100rps.
Debug
from scrapy.utils.response import open_in_browser open_in_browser(response) from scrapy.shell import inspect_response inspect_response(response, self)
It is possible to debug xpaths in Google Chrome browser console:
$x('//h1/a/text()')
Scrapy shell
scrapy shell 'http://quotes.toscrape.com/page/1/'
2017-02-12 13:50:08 [scrapy] INFO: Spider opened
[s] Available Scrapy objects:
[s] crawler <scrapy.crawler.Crawler object at 0x1064a6ad0>
[s] item {}
[s] request <GET http://google.com>
[s] response <302 http://google.com>
[s] settings <scrapy.settings.Settings object at 0x1064a6a50>
[s] spider <DefaultSpider 'default' at 0x1084c5490>
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
view and fetch functions are very useful.
Logging
import logging import scrapy class MySpider(scrapy.Spider): # ... def parse(self, response): self.logger.info('A response from %s just arrived!', response.url) # or self.log("Log something ...") # or self.log("Log something ...", level=logging.INFO)
Logging levels:
DEBUGINFOWARNINGERRORCRITICALSILENT(no logging)
Use LOG_LEVEL setting to specify desired logging level.
Logs output tuning:
LOG_ENCODINGLOG_DATEFORMATLOG_FORMATDUPEFILTER_DEBUGCOOKIES_DEBUG
Logs management:
- Splunk
- Logstash
- Kibana
Memory usage
Deploy
Scrapyd
Modify scrapy.cfg:
[deploy] url = http://localhost:6800 project = myproject
pip install scrapyd-client scrapyd-deploy curl http://localhost:6800/schedule.json -d project=myproject -d spider=myspider
Multiple servers:
[deploy:server1] url = http://server1:6800 [deploy:server2] url = http://server2:6800
scrapyd-deploy server1
Priority
Default task priority is 0.
To set another priority use priority setting:
curl http://localhost:6800/schedule.json -d project=myproject -d spider=myspider -d priority=1
Scrapycloud
Use shub utility.
Performance
Autothrottle addon is enabled by default on scrapycloud.
It may cause a few times slower scraping rate, sometimes 5 times or more.
use AUTOTHROTTLE_ENABLED = false setting to disable it.
Each spider execution requires extra ~30 seconds to start on scrapycloud. So 1 spider does 100 requests is much better than 100 spiders each sends only 1 requests.
In case if you use blocking db client, you'll, probably, see effect of it. Blocking db clients performs fine if connection is fast: db located on the same server or network.
Example, a few db requests on local network vs the Internet: 57ms vs 1.19s.
Custom images
Use cases: add custom binaries, choose another framework for scraping (like use aiohttp).
Dockerfile
FROM python:3.6-slim RUN mkdir -p /app WORKDIR /app ADD . /app RUN pip install -r requirements.txt RUN ln -s /app/scripts/start-crawl /usr/sbin/start-crawl RUN ln -s /app/scripts/list-spiders /usr/sbin/list-spiders RUN chmod +x /app/scripts/start-crawl /app/scripts/list-spiders ENV PYTHONPATH "$PYTHONPATH:/app"
.dockerignore
*.pyc */*.pyc */*/*.pyc */*/*/*.pyc */*/*/*/*.pyc .env .git .idea .DS_Store .releases
Logging; saving scraped items, requests
For logging use Scrapy Cloud Write Entrypoint, see the code.
scrapinghub.yml
projects: default: 12345 images: default: myuser/myrepository
Scripts
scripts - list-spiders - start-crawl
list-spider:
#!/usr/local/bin/python import re import sys def list_spiders(): print("myspider") if __name__ == '__main__': sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0]) sys.exit(list_spiders())
start-crawl:
#!/usr/local/bin/python import re import sys from myproject.app import main if __name__ == '__main__': sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0]) sys.exit(main())
Settings
import json import os SHUB_SETTINGS = json.loads(os.getenv('SHUB_SETTINGS', '{}')) project_settings = SHUB_SETTINGS.get('project_settings', {})
Deploy
Use shub command line tool.
shub image build shub image push --username=<docker hub username> --password <docker hub password> --email <docker hub email> shub image deploy <scrapycloud project name> --username=<docker hub username> --password <docker hub password> --email <docker hub email>
Troubleshooting
Run build with --debug key:
shub image build --debug
sh into the image:
docker run -it <container id> bash
On OSX I have an error when I run shub image build for first time:
Detected error connecting to Docker daemon's host.
Try this to solve it:
docker-machine restart default eval $(docker-machine env default)
Best practices
Avoid denial-of-service attack
Use throttling, watch response time.
Copyrights
Look at the copyright notice of the site.
Proxies
Use HttpProxyMiddleware (enabled by default) and http_proxy (https_proxy) environment variables.
Crawlera is a smart downloader designed specifically for web crawling and scraping. It allows you to crawl quickly and reliably, managing thousands of proxies internally, so you don’t have to.
Saving to a database
Batch insert usually is more efficient way.
Spider name
If the spider scrapes a single domain, a common practice is to name the spider after the domain, with or without the TLD. So, for example, a spider that crawls mywebsite.com would often be called mywebsite.
User-Agent
Set User-Agent header to something that identifies you.
Crawling in large scale
Easy to grow horizontally, just add more spiders, more machines.
But, in order to be able to crawl faster, we may need to scale vertically (more CPU, more bandwidth) or build a cluster with each spider effort coordinated (distribute requests to the same domain across many machines).
See scrapy cluste.
Scraping js generated content
Use lightweight browsers without GUI.
See Splash.
Vocabulary
Scraping
The main goal in scraping is to extract structured data from unstructured sources.
UR2IM
UR2IM:
- URL
- Request
- Response
- Items
- More URLs
JSON Line format
.jl files have one JSON object per line, so they can be read more efficiently.
Thoughts on scraping
Headers may contain Last Modified or even ETag, so this must be enough to understand if a file was changed since last time, no need to download the file, only get headers.
If you persist raw responses or extracted data on s3, you may not need a database to store meta information, use s3 object meta only.
Scraping data grouped in lists
See Automatic Wrapper Adaptation by Tree Edit Distance Matching.
MDR library on GitHub.
Links
Learning Scrapy by Dimitrius Kouzis-Loukas